
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 메타인지 생각의 기술 독후감
- 30대 필독서
- 메타인지 책 요약
- 30살 추천 도서
- 목적 찾는 법
- 자신에게 할 질문
- 책 추천
- 자기계발서 추천
- 몰입하는 방법
- 플로우 방법
- 맥 받아쓰기
- 몰입 책 후기
- 글로벌 MBA
- mac 받아쓰기 설정
- 받아쓰기 설정
- 온라인 파트타임 MBA
- 20살 추천 도서
- 30대 필독
- 자산 책 추천
- 자기객관화 방법
- 자기성찰 자기계발서 추천
- 강자의 언어
- 글로벌 MBA 비용
- 오디오 텍스트 변환
- 몰입 줄거리
- 청소년 추천 도서
- 돈의 속성이란
- 생각의 기술 리뷰
- MBA 비용
- 자산늘리는법
Archives
- Today
- Total
Let's enjoy our life
[Python] ML - unsupervised text classification for word labeling / toptic modeling python 단어 라벨링 투척! 본문
Study/Python
[Python] ML - unsupervised text classification for word labeling / toptic modeling python 단어 라벨링 투척!
IT파스칼 2023. 10. 18. 13:24과제에 쓰일 자료를 정리한 목적입니다. 방대한 단어들을 그룹화하려는 것이 목적입니다.
1. Latent Derilicht Analysis ( LDA ) Conquered
- Documents with similar topics will always have similar set of words.
- Groups are formed by searching group of words that frequently appear in document. (이미 있는 것을 사용할 것임)
- User has to input/provide the value of ‘ K ‘ i.e number of topics in a document.
- Documents are assumed to be probability distributions over topics.
- Topics are assumed to be probability distributions over words used in documents.
여기 방법이 잘 나와있고 이해하기도 쉬움.
그룹화할 수를 정하면 비슷한 단어끼리 묶임.

비슷한 단어끼리 묶인 것을 카테고리화(Topic)으로 구별.
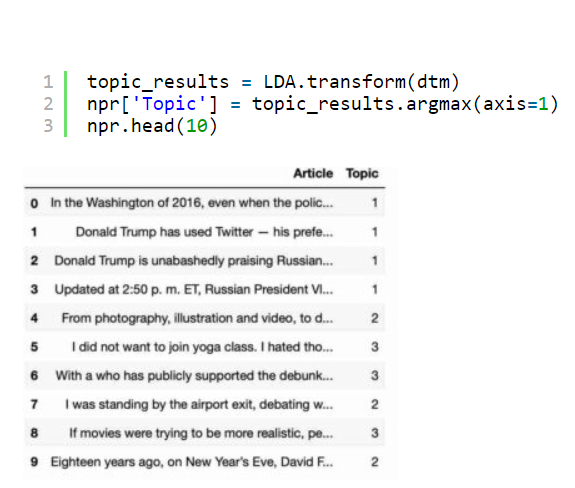
1.3 Assigning Cluster names
위에 토픽으로 구별한 것을 수작업으로 각 토픽의 이름을 정해줘야함. (단계 1)
이걸 자동으로 할 수 있을지는 더 찾아봐야할 것 같음.
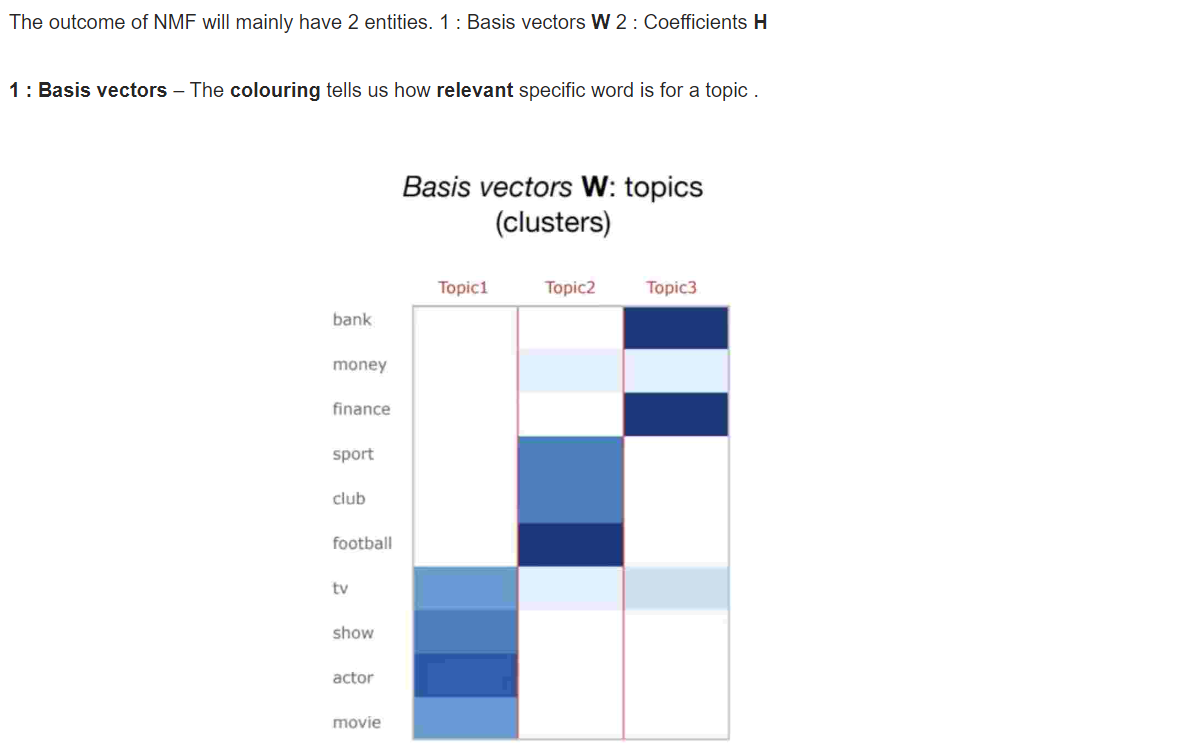
2. Non-negative Matrix factorization ( NMF) Conquered
단어 수가 많을때 사용하면 유용한 모델!
만개정도(?) 넘어갈때 사용하나봐요.
위 모델의 결과 값 미리보기 ▼
https://www.herevego.com/unsupervised-text-class-python/
Unsupervised Text Classification In Python - Home
Unsupervised text classification using python using LDA ( Latent Derilicht Analysis ) & NMF ( Non-negative Matrix factorization )
www.herevego.com
'Study > Python' 카테고리의 다른 글
| [Python] ModuleNotFoundError: No module named 'inflect' 주피터 노트북 에러해결 (0) | 2023.10.20 |
|---|---|
| [Python] OSError: [E050] Can't find model 'en_core_web_sm'. It doesn't seem to be a Python package or a valid path to a data directory. 에러 해결 방법 - Jupyter Notebook 주피터 노트북 (0) | 2023.10.19 |
| Auto GLM (0) | 2021.02.22 |
| 더미변수 전환, 전환 되돌리기 파이썬 코드 (Dummy variable Python code) (0) | 2021.02.04 |
| 파이썬 회귀분석 팁 (0) | 2021.02.04 |
'Study/Python' Related Articles
more




Comments