
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- mac 받아쓰기 설정
- 자산늘리는법
- 몰입 줄거리
- 플로우 방법
- 돈의 속성이란
- 목적 찾는 법
- 강자의 언어
- 20살 추천 도서
- 글로벌 MBA
- 내 장점 찾기
- 맥 받아쓰기
- 책 추천
- 30살 추천 도서
- 강점 5가지
- 받아쓰기 설정
- 자신에게 할 질문
- 온라인 파트타임 MBA
- 블랙쉽
- MBA 비용
- 몰입하는 방법
- 장점 5가지
- 내 강점
- 몰입 책 후기
- 30대 필독
- 자기계발서 추천
- 오디오 텍스트 변환
- 30대 필독서
- 글로벌 MBA 비용
- 청소년 추천 도서
- 자산 책 추천
- Today
- Total
Let's enjoy our life
Pycaret 설치 코드 - 파이썬(python) AutoML 구현 예제 본문
AutoML(오토ML) 이란?
데이터 성격에 맞게 자동으로 데이터 분석 모델을 추천해주는 Auto Machine Learning 기법
AutoML(오토ML) 장점
- 인공지능 분석 모델을 학습하기 위해 데이터에서 중요한 특징(feature)을 선택하고 인코딩하는 방식에 대한 특징 엔지니어링(feature engineering) 자동으로 추출한다.
- 인공지능 모델 학습에 필요한 사람의 설정들, 하이퍼파라미터를 자동으로 탐색해 주는 것이다.
- 인공지능 모델의 구조 자체를 더 효율적인 방향으로 찾아주는 아키텍처 탐색이다.
2020년 11월에 업데이트된 파이썬 머신러닝 라이브러리 기능입니다. 생각보다 많은 알고리즘을 추천해줘서 간편하게 쓰일 것 같습니다. 추천 알고리즘 기능이 생각보다 퍼포먼스가 잘 나와서 앞으로 몇 년 뒤에는 파라미터까지 자동으로 선정해주는 알고리즘이 나올지도 모르겠네요.
Juypter Notebook 환경에서 아래코드로 Pycaret을 설치해줍니다.
pip install pycaret
Successfully Installed !
밑에 빨간 에러 메시지가 나와도 깔끔하게
"무시"하셔도 됩니다.
버전이 달라지면 pip 명령어를 쓸 수 없다 하는데 이미 오늘은 2021년도이고
pip 명령어는 잘 쓰고 있는...
저 에러 메시지가 보기 싫으신 분들은 아래 코드를 사용하신 후 Pycaret을 설치해주시면 됩니다.
# pip 버젼 확인 python -m pip install --upgrade pip pip install example --use-feature=2020-resolver
데이터 셋 설명 (Dataset Acknowledgement)
"Sarah Gets a Diamond"
이 사례는 Darden School of Business(University of Virginia)의 1년 차 의사결정 분석 과목에서 쓰였습니다. 결혼에 낭만적인 꿈이 있는 한 MBA 학생이 예비 신부 사라에게 적합한 다이아몬드를 선택하는 사례입니다.
Dataset Acknowledgement:
This case was prepared by Greg Mills (MBA ’ 07) under the supervision of Phillip E. Pfeifer, Alumni Research Professor of Business Administration. Copyright (c) 2007 by the University of Virginia Darden School Foundation, Charlottesville, VA. All rights reserved.
Y 컬럼: Price
from pycaret.datasets import get_data dataset = get_data('diamond')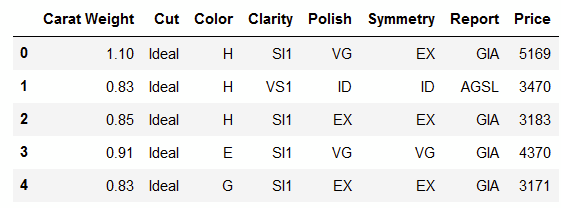
데이터 준비 (Getting the Data)
모델링을 위해 데이터 분할을 해줍니다.
randome state를 789으로 해줘서 90% :10%으로 훈련 데이터, 테스트 데이터를 나눕니다.
data = dataset.sample(frac=0.9, random_state=786) data_unseen = dataset.drop(data.index) data.reset_index(drop=True, inplace=True) data_unseen.reset_index(drop=True, inplace=True) print('Data for Modeling: ' + str(data.shape)) print('Unseen Data For Predictions: ' + str(data_unseen.shape)) # Data for Modeling: (5400, 8) # Unseen Data For Predictions: (600, 8)모델 환경 설정 (Settinf up Environment in PyCaret)
분석 모델을 돌리기 전에 종족 변수 (y, Target)을 지정해줍니다.
pycaret은 독립변수(x, factor)의 유형을 자동으로 지정해주는 점이 또 하나의 장점입니다. 독립변수의 데이터 유형을 정의하는 것이 중요한 이유는 전에 포스팅했던 글에 자세히 나와있습니다. (유형의 중요성: 2021.01.12 - [Study/기초 통계] - 변수의 종류와 척도의 종류 - 통계 개념 1분 정리 [빅데이터 분석 기초 다지기])
# 자동으로 데이터 유형 지정 from pycaret.regression import * exp_reg101 = setup(data = data, target = 'Price', session_id=123)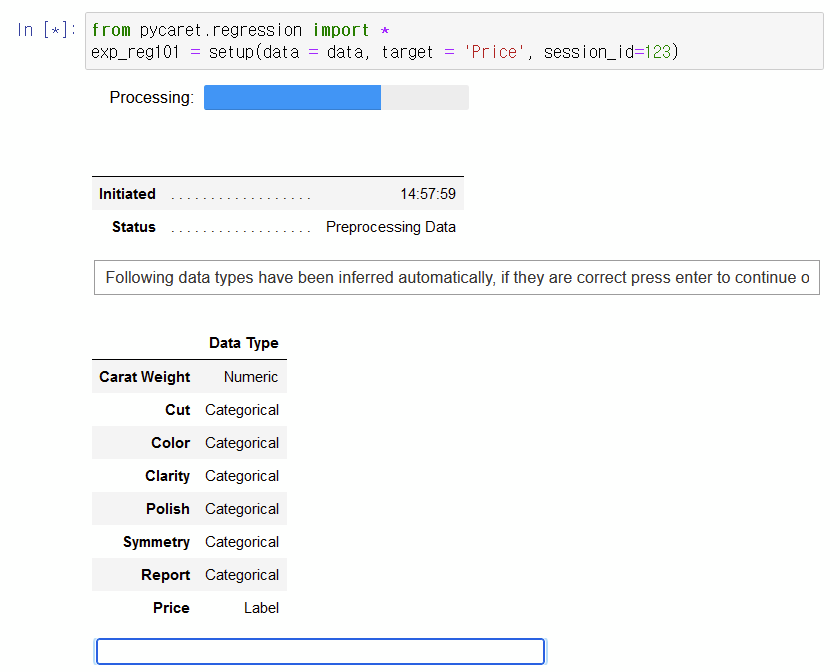
위의 코드를 실행하면 저렇게 파란 블랭크 박스가 나오면 enter 키를 눌러줍니다.
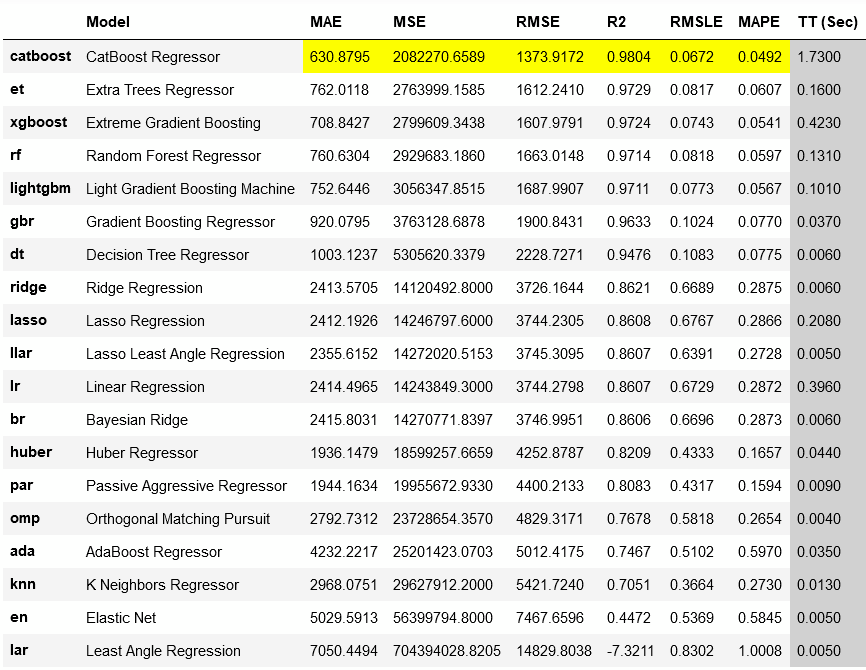
다음 데이터 셋에 알맞은 알고리즘을 추천하는 코드를 실행합니다. 추천 방식은 각 알고리즘 결과의 MAE, MSE, RMSE, R2, RMSLE, MAPE 점수 들을 비교해 가장 퍼포먼스가 좋게 나오느 모델에 하이라이트 해줍니다 (결과 테이블에 자동으로 하이라이트 됨).
'ransac' (Random Sample Consensus) 방법은 데이터 outlier를 제거해주는 코드입니다. 자세한 코드 설명 참조 [https://pycaret.readthedocs.io/en/latest/api/regression.html]
# 모델 추천 코드 실행 best = compare_models(exclude = ['ransac'])
compare_models 코드는 20가지의 각 모델별 MAE, MSE, RMSE, R2, RMSLE와 MAPE와 프로세스 시간(TT sec)을 비교해줍니다. 코드 실행 후 아래의 결과 테이블에서 확인할 수 있듯이 자동으로 추천 모델을 하이라이트 해줍니다. 여기서 추천 상위 기준은 R2의 점수가 높은 순에서 낮은 순으로 (highest to lowest) 정렬합니다.
- R2 점수가 기준인 것이 default이지만 compare_models(sort = 'RMSLE') sort 방법을 사용하면 비교 기준을 바꿀 수 있습니다.
- 기존 비교 모델들의 개수는 20가지이지만 compare_models(fold = 5) 코드를 사용하면 모델 갯수 조정이 가능합니다. 모델 수를 줄이면 training run time을 감소시킬 수 있습니다.
- 파라미터에 n_select = n 코드를 사용하시면 top n 모델을 반환합니다.
모델 생성 (Create a Model)
위에 추천된 모델 중 3가지를 지정해 각 모델 성능을 비교해보겠습니다. 선정기준은 제 랜덤입니다. 위에 compare_models() 결과의 테이블에서 선택 / 아래 models() 코드를 통해 True 인 모델을 선택해도 됩니다.
models() # shows 25 regressors available in the model library of PyCaret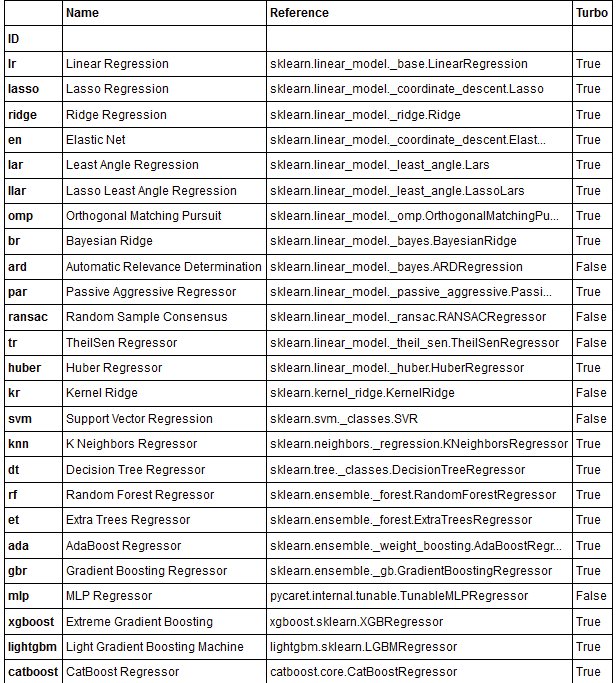
이 세 가지 모델을 가지고 성능 비교를 합니다.
- CatBoost Regressor '(catboost')
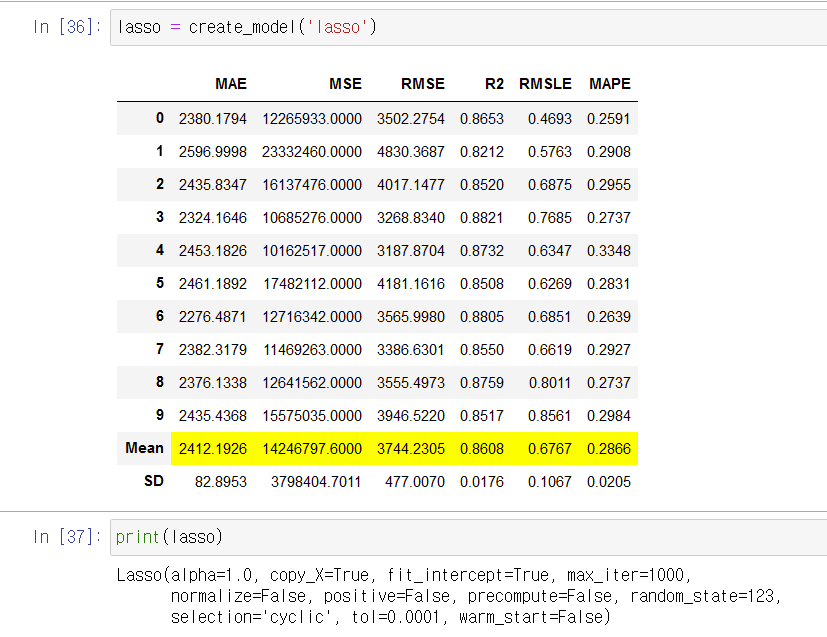
- Lasso Regression ('lasso')
- Decision Tree ('dt')
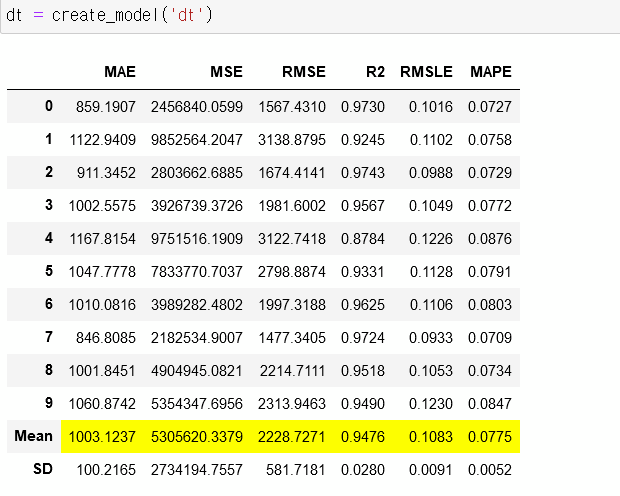
# CatBoost Regressor catboost = create_model('catboost') # 자동으로 아래 표 return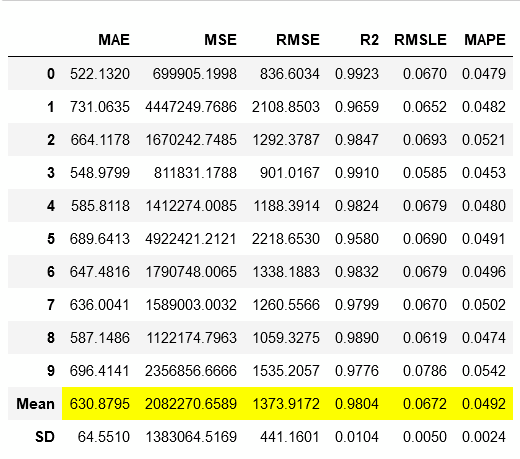
create_model() 은 이름에서 설명하는 것과 같이 모델 파라미터들을 cross validation과정을 통해 스스로 훈련시키고 검증합니다 (하이퍼 파라미터 탐색 자동화). 위 테이블에서 하이라이트 된 것과 같이 점수를 보여줍니다. 그리고 이제 지정한 모델을 print 하면 파라미터의 정보를 알 수 있습니다. catboost의 파라미터 정보는 클라스에 저장됨으로 다른 모델을 보도록...
print(catboost) # print(catboost) 결과 # <catboost.core.CatBoostRegressor object at 0x000001408D4A4A00>
▼ lasso 파라미터 결과
Lasso(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=1000, normalize=False, positive=False, precompute=False, random_state=123, selection='cyclic', tol=0.0001, warm_start=False)
▼ decision tree 파라미터 결과
DecisionTreeRegressor(ccp_alpha=0.0, criterion='mse', max_depth=None, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort='deprecated', random_state=123, splitter='best')

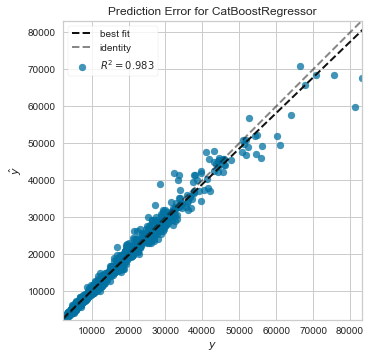
모델 결과 (Plot a Model)
Residuals Plot, Prediction Error, Feature Importance을 통해 모델 성능을 비교할 수 있습니다. 아래 테이블과 같이 다른 모델 성능 확인을 할 수 있는 방법들이 있습니다.
Classification
| Name | Plot |
| Area Under the Curve | ‘auc’ |
| Discrimination Threshold | ‘threshold’ |
| Precision Recall Curve | ‘pr’ |
| Confusion Matrix | ‘confusion_matrix’ |
| Class Prediction Error | ‘error’ |
| Classification Report | ‘class_report’ |
| Decision Boundary | ‘boundary’ |
| Recursive Feature Selection | ‘rfe’ |
| Learning Curve | ‘learning’ |
| Manifold Learning | ‘manifold’ |
| Calibration Curve | ‘calibration’ |
| Validation Curve | ‘vc’ |
| Dimension Learning | ‘dimension’ |
| Feature Importance | ‘feature’ |
| Model Hyperparameter | ‘parameter’ |
Regression
| Name | Plot |
| Residuals Plot | ‘residuals’ |
| Prediction Error Plot | ‘error’ |
| Cooks Distance Plot | ‘cooks’ |
| Recursive Feature Selection | ‘rfe’ |
| Learning Curve | ‘learning’ |
| Validation Curve | ‘vc’ |
| Manifold Learning | ‘manifold’ |
| Feature Importance | ‘feature’ |
| Model Hyperparameter | ‘parameter’ |
참고: https://pycaret.org/plot-model/
plot_model(catboost) plot_model(catboost, plot = 'error') plot_model(catboost, plot='feature') evaluate_model(catboost)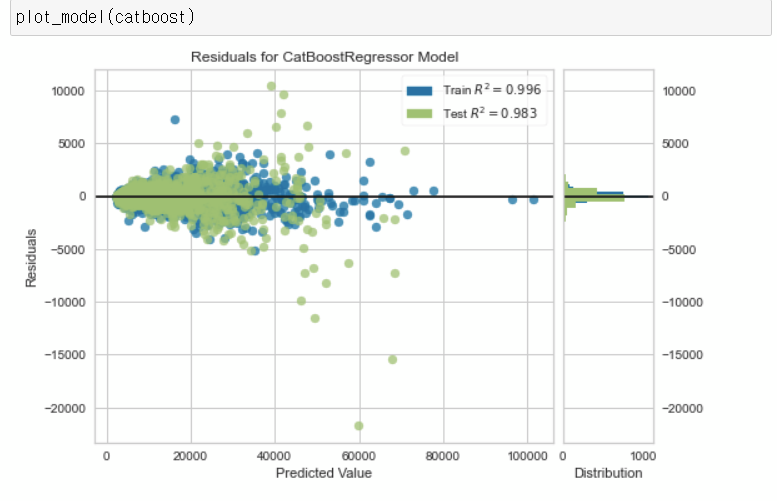
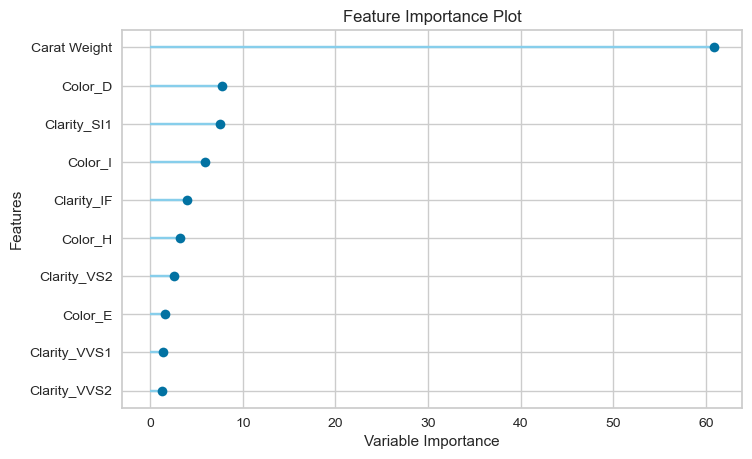

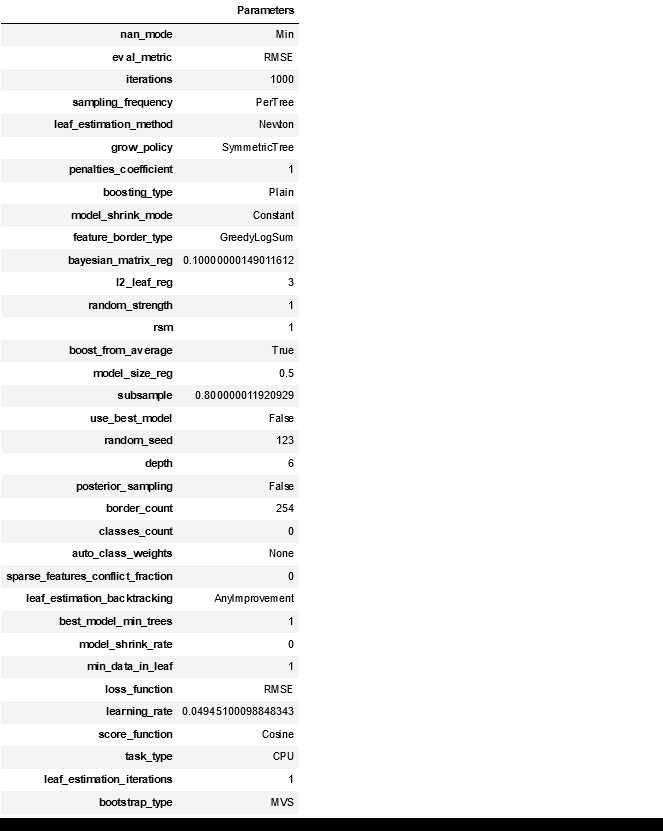
모델 성능까지 알아보았습니다.
다음 포스팅엔 모델 성능을 위해 모델 튜닝하는 방법과 모델 튜닝 전과 후 성능 비교를 해보겠습니다.
모델 튜닝이 중요한 이유는 결과 양상을 보고 문제점을 진단하고 분석 모델이 더 나은 성능을 가질 수 있도록 실험하는 것입니다. 더 나은 하이파라미터를 찾기 어려웠는데 이젠 AutoML을 통해 컴퓨터가 알아서 해줍니다.
[참고]
AutoML 장점 - https://magazine.hankyung.com/business/article/202101061704b
Pycaret Github -https://github.com/pycaret/pycaret/blob/master/tutorials/Regression%20Tutorial%20Level%20Beginner%20-%20REG101.ipynb
GitHub - pycaret/pycaret: An open-source, low-code machine learning library in Python
An open-source, low-code machine learning library in Python - GitHub - pycaret/pycaret: An open-source, low-code machine learning library in Python
github.com