
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 몰입하는 방법
- 몰입 줄거리
- 글로벌 MBA 비용
- 돈의 속성이란
- 목적 찾는 법
- 자기계발서 추천
- 플로우 방법
- 블랙쉽
- 오디오 텍스트 변환
- 30살 추천 도서
- 30대 필독서
- 내 강점
- 온라인 파트타임 MBA
- 책 추천
- 맥 받아쓰기
- 장점 5가지
- 몰입 책 후기
- 자산 책 추천
- 자산늘리는법
- 자신에게 할 질문
- 내 장점 찾기
- MBA 비용
- 청소년 추천 도서
- 글로벌 MBA
- 강자의 언어
- 30대 필독
- 20살 추천 도서
- 강점 5가지
- 받아쓰기 설정
- mac 받아쓰기 설정
- Today
- Total
Let's enjoy our life
회귀분석 본문
1.회귀분석소개
비용함수 Parameter vector
낮은 쪽 반복
경사하강법
Feature의 개수가 하나인 경우 (n=1): 기울기를 알파 만큼 뺀다
비용함수값이 거의 변하지 않을때 min 지점에 도달했다고 간주
Feature의 개수가 하나인 경우 (n>=2): 편미분이 1이상
경사하강법 적용
Feature Scaling: Gradient descent의 실제 적용
Feature값의 단위가 서로 다를 수 있기 때문에 미분하는 과정에서 움직임의 폭이 불규칙하다.
이럴 경우 모든 feature들의 값의 범위를 아주 비슷하게 축소한다. (Feature Scaling을 하는 이유)
feature가 비슷한 범위에 있으면 반복하는 과정에서 안정적으로 수렴이 가능하다.
경사하강법 적용 방법
1) 표준화 (Standardization)
Random Variable에서 또는 샘플에서 평균을 뺸다 = THEN feature 샘플 평균 turn into ZERO
평균을 뻇기 때문에 범위가 줄어들 것 => 평균을 뺀 값에서 표분편차(Standard normal distribtion)로 나눠진다.
평균 0, 분산 1의 범위 내에서 모든 feature들이 움직인다. (0을 중심으로 ±α 값: 68%, ±2α 값: 95%, ±3α 값 99% range
학습속도: 엔지니어가 선텍해야한다
알파값(학습속도)이 너무 작을 경우: 수렴속도가 느리다 | 클 경우: 발산 가능성 = 적절한 선택이 중요 (작은 값에서 큰값으로 바꿔주면서 iternation 실행)
OLS 선형회귀
파라미터 구하는 법: Residual의 최소화 (잔차제곱의 합을 최소화하는 θ 비용함수를 OLS추정치로 함)
Overfuitting 문제 (= High variance 문제) > 설명력이 떨어짐
정규화를 통해서 OLS문제를 해결하는 접근법
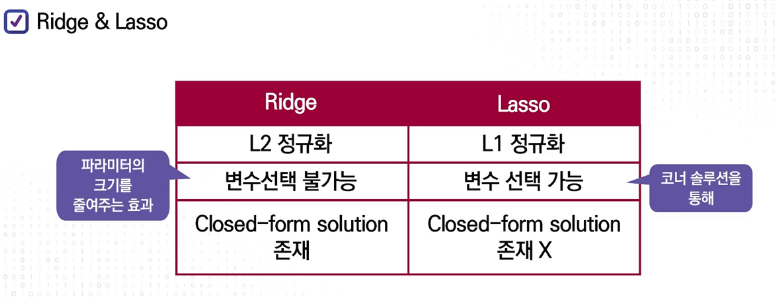
1) Ridge Regression
> L2(L2 norm) 정규화를 통해서 해결
> element의 제곱을 합해서 스퀘어 루트
> 잔차제곱합 + 패널티 항 (파라미터가 크면 패널티가 크게 됨) ∴ 파라미터값의 최소화
> 람다 λ Shrinkage (축소)의 정도를 조정, 통상 0 보다 큼, λ가 클 경우 계수들이 0으로 수축
이러한 정규화를 통해서
> 예측의 정도, 정확도가 높아짐 & 0계수 추적양의 bias 편차와, variance간의 상관관계를 최적화, Feature들 간의 다중공선성 문제 해결
= PCA (Principal Component Analysis)와 상당한 연관성이 있다
2) Lasso Regression
Lasso: Least Absolute Shrinkage and Selection Operator
L1 정규화를 통해서 해결
- L1 행렬에서 L1 norm은 절대값의 합으로 거리를 표현 => 회귀계수의 절대값 합을 패널티 항으로 사용
- 패널티의 shrinkage를 조정하는 람다 가 조절
단, 절대값이기 때문에 최적값이 코너 솔루션이 될 확률이 릿지에비해 상당히 높다. 파라미터가 제로가 되면 그 feature는 없어지게됨 => feature selection 효과 (이 경우, 흔히 정보 손실, 정확도 감소가 나타나지만 과적합 문제는 해결된다)

3) Elastic Net Regression (Ridge와 Lasso를 동시에 포함)
- 릿지와 라쏘의 장점을 모두 가지고 있어 변수의 수도 줄이고 variance도 줄이고 싶을 때 사용 가능
다중공선성(多重共線性)문제(Multicollinearity)는 통계학의 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나는 문제이다. 독립변수들간에 정확한 선형관계가 존재하는 완전공선성의 경우와 독립변수들간에 높은 선형관계가 존재하는 다중공선성으로 구분하기도 한다.
6.2 다양한 회귀분석 모델
1) 선형회귀분석
Stock return pricing 모델
CAPM: Capital Asset Pricing Model = 시장요인 (Market factor) 하나만을 가지고 설명 = 설명력 부족
그래서,
1993년 Fama-French가 두 가지 요인(규모요인, 가치요인)추가 => 3요인 모형
그리고,
2015년, 다시 두 가지 요인 추가 (수익성 요인, 투자 요인) => 5요인 모형
- marker factor = 시장의 index 수익률에서 risk free asset return을 뺀 요인
베타: 개별 주식 i와 market return과의 normalised covariance = covariance /market variance
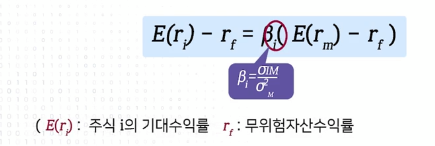
공분산 (covariance)은 2개의 확률변수의 선형 관계를 나타내는 값이다. 만약 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값도 상승하는 선형 상관성이 있다면 양수의 공분산을 가진다. 반대로 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값이 하강하는 선형 상관성을 보인다면 공분산의 값은 음수가 된다. 이렇게 공분산은 상관관계의 상승 혹은 하강하는 경향을 이해할 수 있으나 2개 변수의 측정 단위의 크기에 따라 값이 달라지므로 상관분석을 통해 정도를 파악하기에는 부적절하다.
[참고 위키피디아] https://ko.wikipedia.org/wiki/%EA%B3%B5%EB%B6%84%EC%82%B0
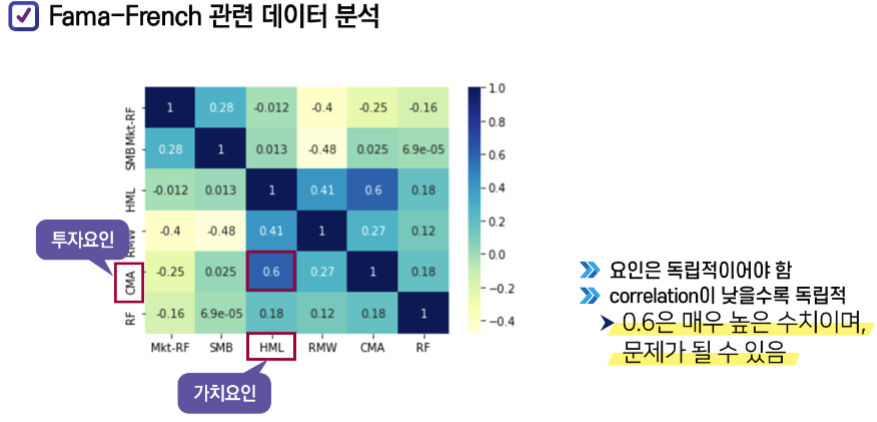
규모요인 (SMB): r(Small cap) - r(Large cap)
가치요인 (HML): Book to marker ratio -> Book value ↑ 가치기업, Market value ↑성장기업
수익성 요인 (BMW): small & big company's 수익성 차이
투자 요인 (CMW): 공격적 & 보수적으로 투자하는 기업들의 수익률을 비교
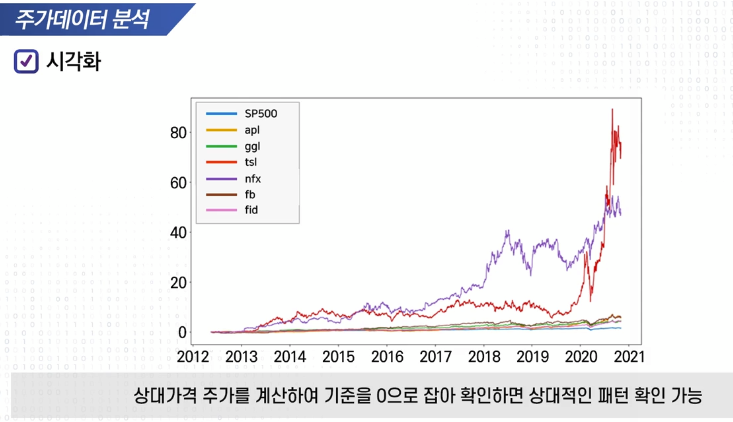
수익률 기초 통계 실습 Python
Adj close: 조정종가

std를 살펴보아야함 (평균이랑 비교) -> 기대수익률과의 관계 확인
Index: 평균은 낮지만 그에따라서 위험도 낮음
개별 주식: 기대수익률은 높지만 위험도 상당히 큼
왜도와 첨도 확인
- 첨도는 간접적인 risk meaure 이 경우 leptokurtic = fat tail 모양 (< 3 이기 때문)
- 왜도는 -value와 +value가 보이는데 +value 일 경우 상승을 많이 한 주식의 패턴
히스토그램 그래프를 통해 회사별 분산 패턴 비교 가능
통계학에서 분포(distribution) 또는 변산성(variability)은 한 분포에 위치하는 여러 점수들이 집중 경향에서 퍼져 있는 성질을 전제하면 '일정한 범위(range)에 흩어져 퍼져 있는 값'으로 정의할 수 있다.

5 가지 요인
ff5 = pdr.DataReader('F-F_Research_data_5_Factors_2x3', 'famafrench', start, end)[0]
ff5.tail()
요인들을 상관관계 그래프로 확인하기
선형회귀 OLS를 통해 분석
R-Squared: 0.961 (96%의 index의 움직임을 5요인이 설명) =모든 요인을 적용했기때문에 높게 나올수 밖에 없음.
함수를 이용하여 모형을 시장요인, 3요인, 5요인 동시에 추정
Apple 예) 개별주식의 경우 설명력을 높이기 어려움
TSLA 예) 요인모형으로 설명되지 않는 부분이 많음
Fama-French의 포트폴리오 조합: 포트폴리오의 수익률은 요인들로 잘 설명됨 (small company -> Positive)
대형주 예) 규모 요인이 통계적으로 유의하지 않음 negative 설명력이 없음